
Vector Databases Explained Simply
Nov. 26, 2024 by @anthonynsimon
Picture this: you run an online shop with thousands of products.
To help users find what they're looking for, you've added a search bar. That way, users can type what they're interested in, and you can show them relevant products.
So for example, when a user types "summer", you might show things like shorts, dresses, hats, and beach umbrellas.
How would you implement this?
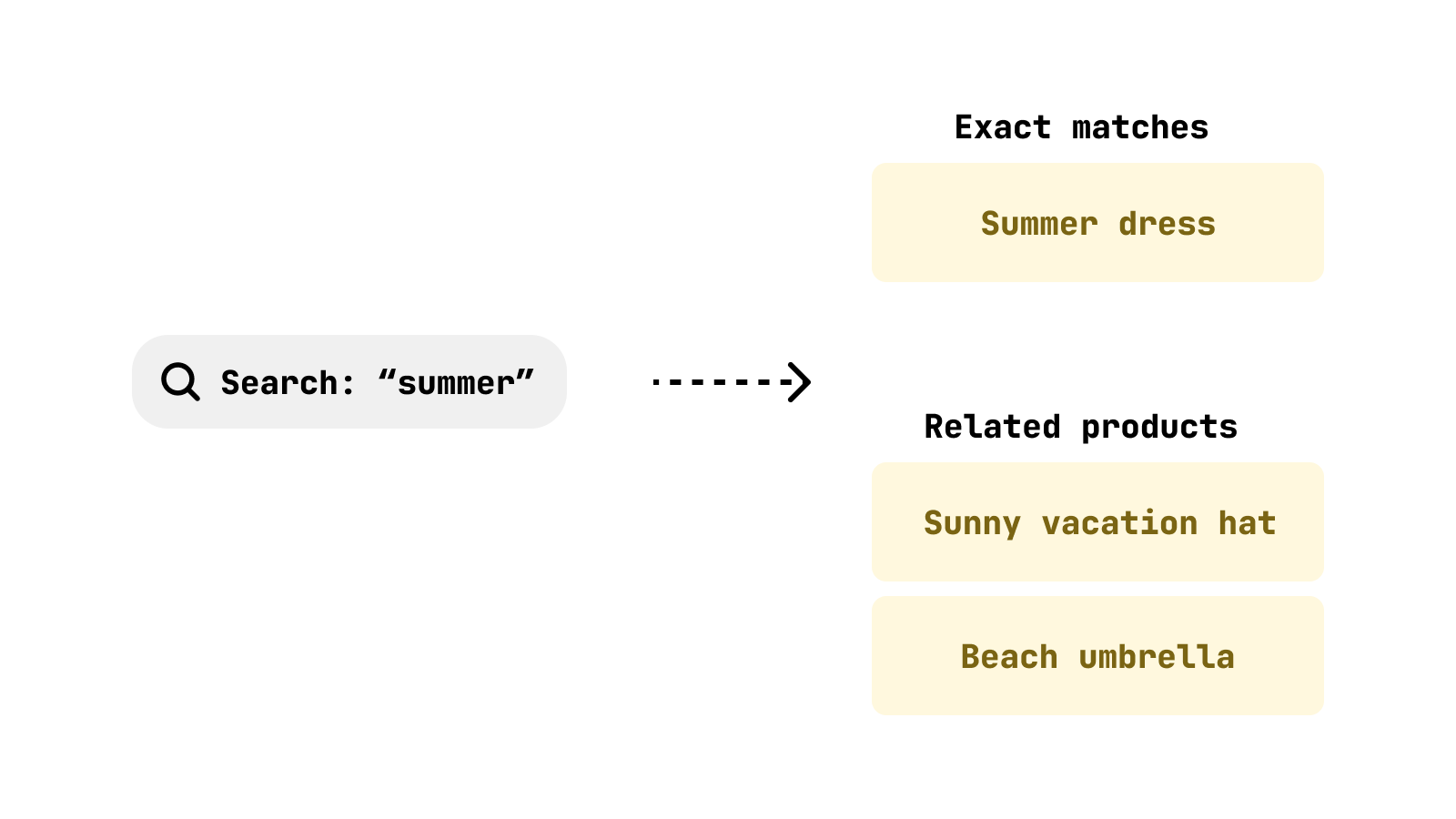
If you're using a relational database like Postgres or MySQL, you might run a query to match products containing the words the user searched for.
But here's the catch: if the user searches for "summer", the database will filter out products that don't explicitly contain that word - you'll miss products like "sunny vacation hat" or "beach umbrella".
To illustrate the issue, let's say you have a table of products like this:
| ID | Name |
|---|---|
| 1 | Summer dress |
| 2 | Sunny vacation hat |
| 3 | Beach umbrella |
| ... | ... |
| 999 | Winter coat |
Let's run a query to find products with "summer" in the name:
SELECT * FROM products WHERE name LIKE '%summer%';
=> Found 1 result
=> Product(id=1 name="Summer dress")
That's correct, the "Summer dress" was found. But what about the "Sunny vacation hat" and "Beach umbrella"? They could be what the user is looking for, but they won't show up in the search results.
These are not misspellings, so fuzzy search won't help here. The database can't find these products because it doesn't understand that they're related to "summer" in a broader sense.
That's where vector databases come in.
First things first, what is a vector?
For our purposes, a vector is list of numbers. It's like a coordinate in a multi-dimensional space, where each dimension represents a different feature of the item.
A vector can represent anything: a word, a product, an image, or even past interactions a user had with your app.
So for example, if you were to recommend products to a user, you might use a vector with hundreds of dimensions to represent a product, where each dimension represents a different feature of the product (like color, size, price, season, etc).
You can then compare these vectors to find products that are similar to each other, even if they don't contain the exact same keywords.
What is a vector database?
A vector database is just a database optimized for storing and searching vectors, even with hundreds or thousands of dimensions.
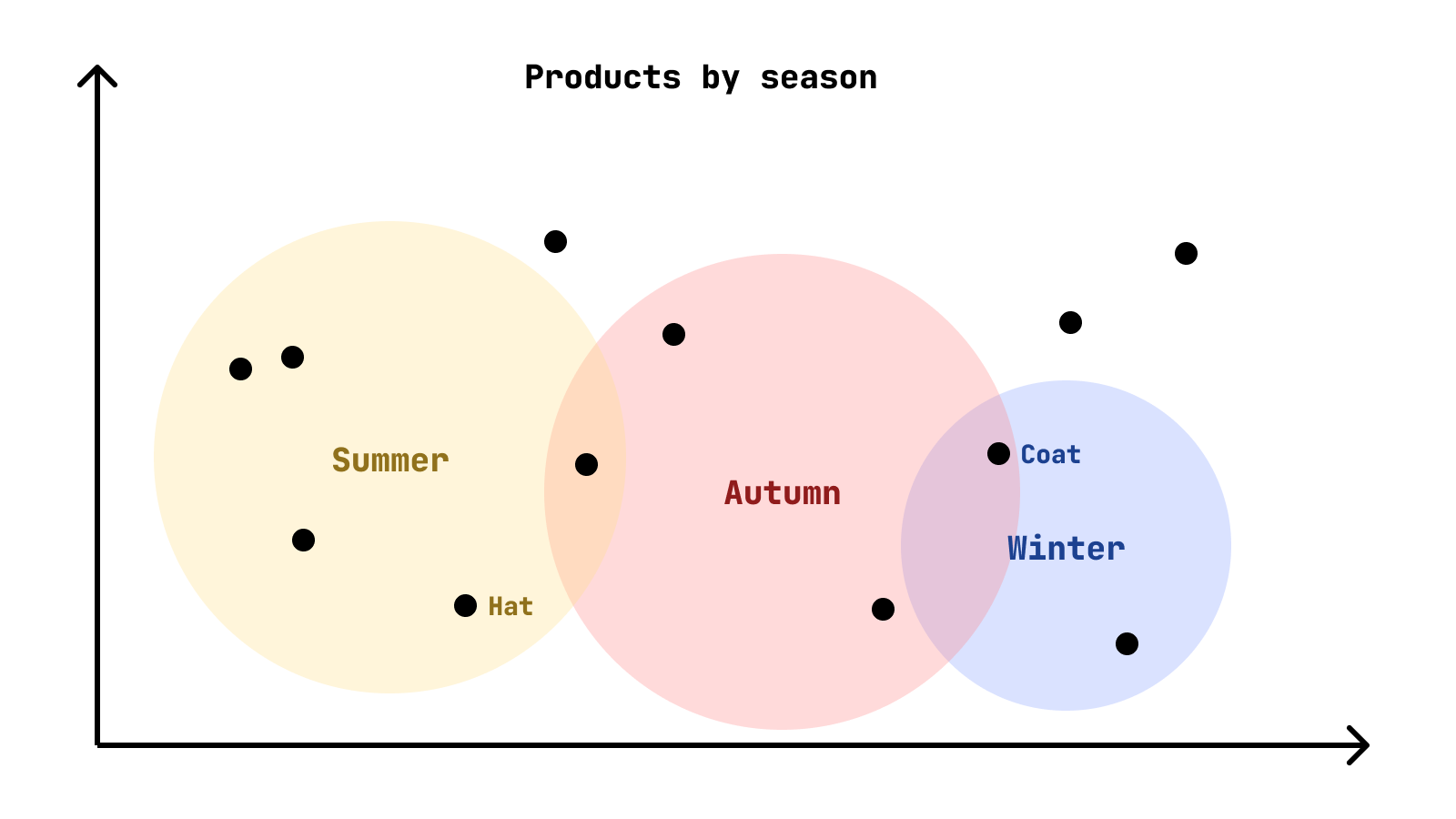
When you query it, instead of looking for exact matches, it finds items based on their proximity.
For example, the vectors for "summer" and "hat" might be placed near each other, while the vector for "winter coat" would be far away.
Example use cases
You can use vector databases for a wide range of applications. Here are some examples:
- Context for chatbots: Retrieve relevant FAQs, documents, or prior conversations to provide better responses. Read more on retrieval-augmented generation (RAG).
- Contextual search: Searches that match queries by meaning, not just word-for-word.
- Personalization: Make recommendations based on what other users with similar tastes liked.
- Memory for LLMs: Act as external memory, helping LLMs recall past interactions or user-specific data.
- Reverse image search: Find similar images based on content or style.
- Music recommendation: Suggest songs based on user preferences or similar tracks.
Essentially, any time you need to find items based on similarity or context, a vector database could help.
How do vector databases work?
Here's a high-level overview of how it all comes together:
1. Create embeddings
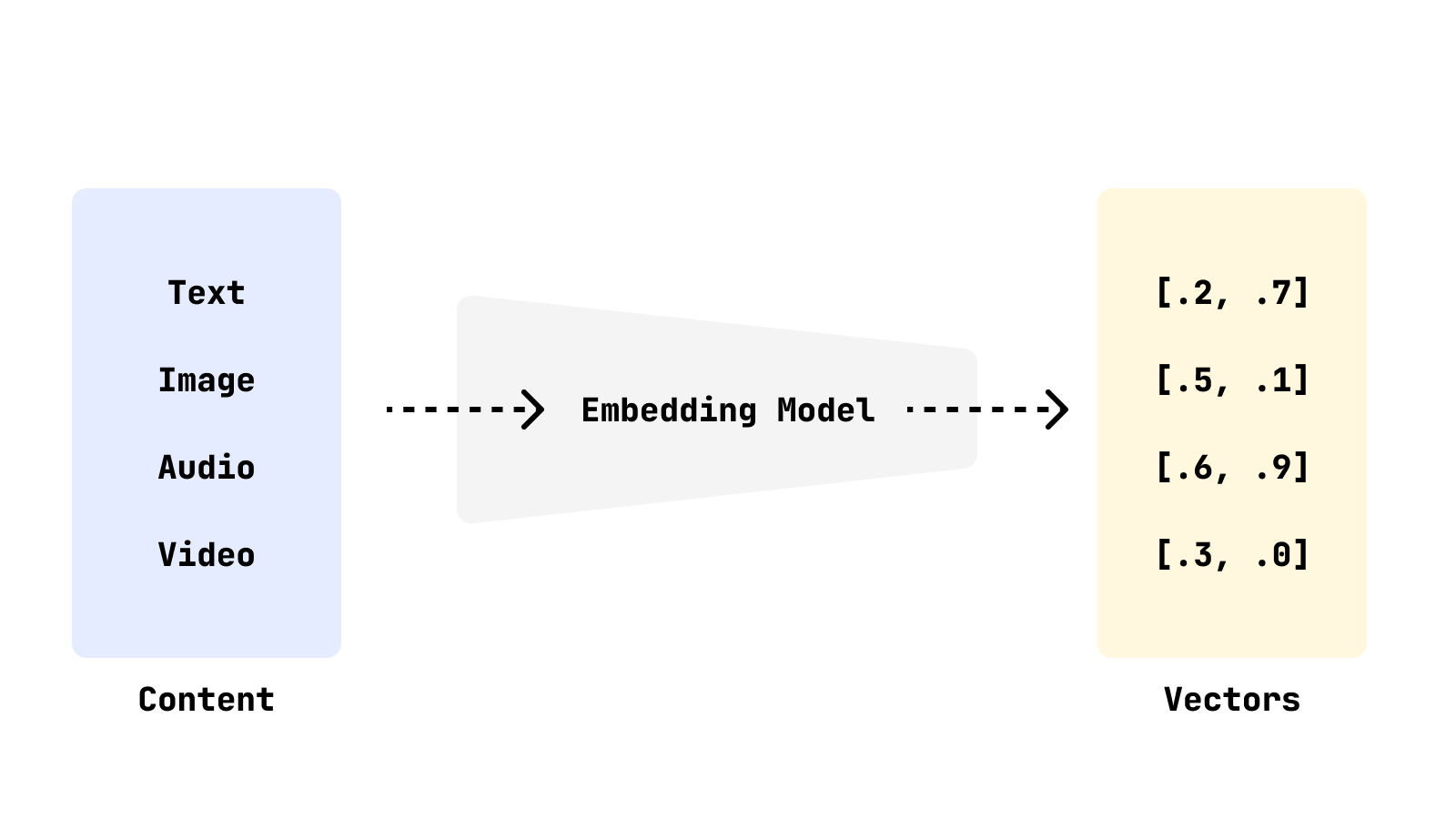
You turn your data (text, images, etc) into vectors using a model like OpenAI or Cohere embeddings, or a lib like SentenceTransformers.
2. Index vectors
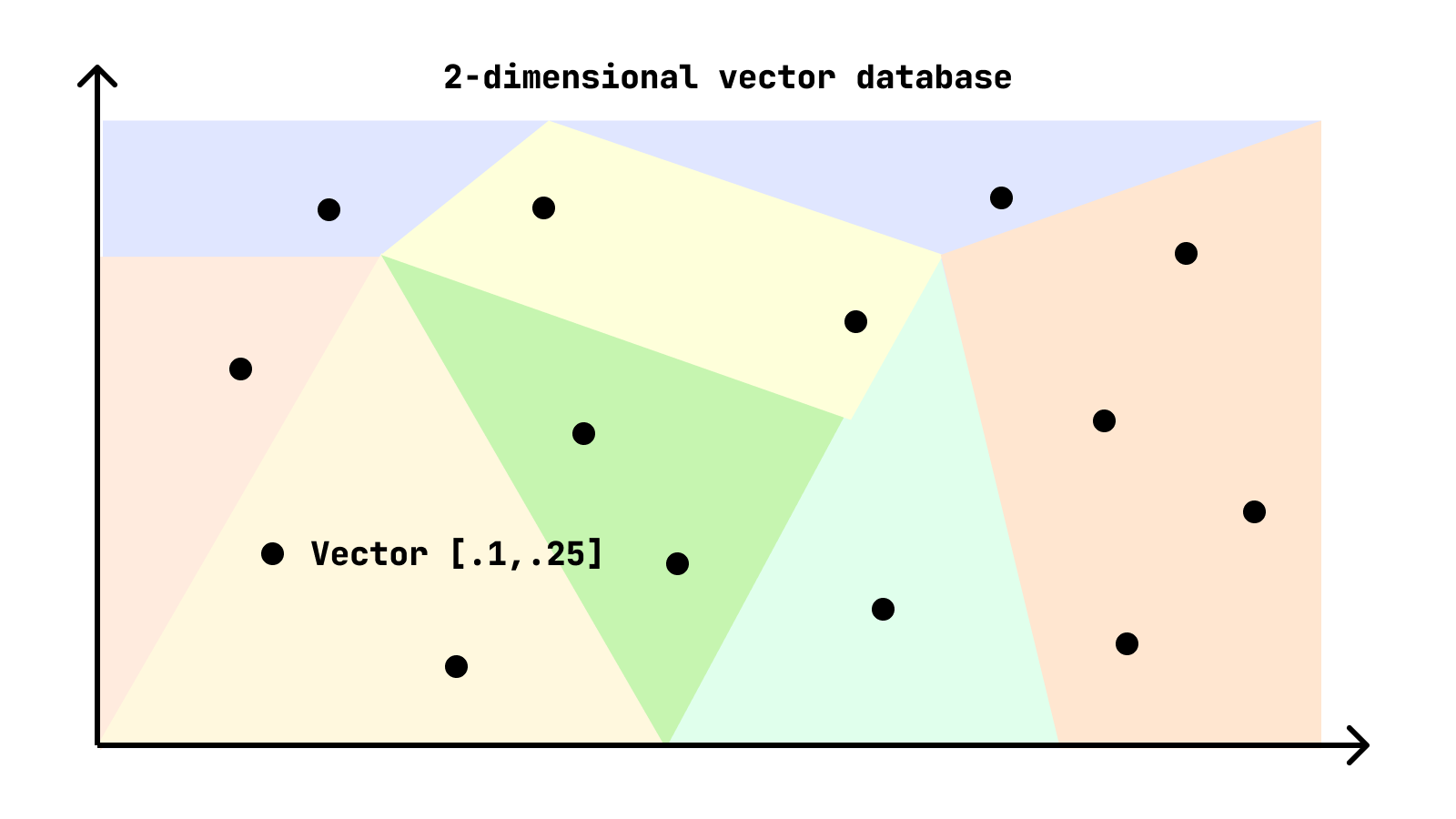
The database will store the vectors in way that makes it easy to query them. This is often done using a technique called approximate nearest neighbors, so the database doesn't have to compare every vector to every other vector in the dataset.
Think of it like a giant map where the closer two points are, the more similar they are. The database will divide the map into regions, so it can quickly find the closest points to a given query.
3. Vector search
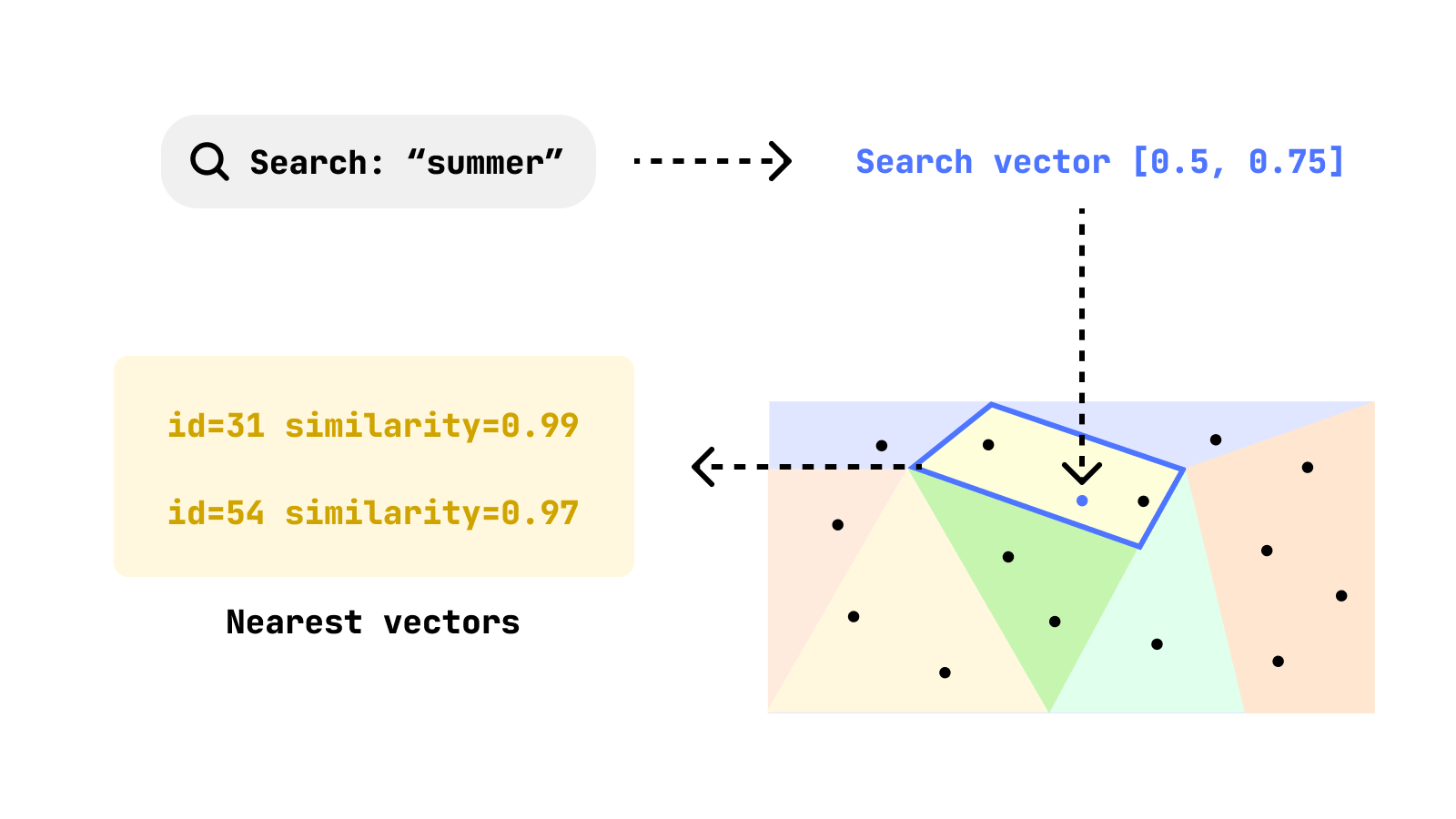
When you run a query, your input gets turned into a vector, and the database looks at the region of the map where your query vector is. From there it can then quickly find the closest vectors to your query since they're in the same region - and that's pretty much it.
This is an overly simplified view, but it gives you an idea of how vector databases work under the hood.
Minimal vector search in pure Python
Now, let's zoom out a bit. If your dataset is small enough, you might not even need a full-blown vector database right away. You could simply iterate over all your vectors and calculate the similarity scores manually.
For the sake of illustration, here’s a Python script that finds the most similar vectors to a query using cosine similarity:
import math
# Example query vector
QUERY_VECTOR = [0.2, 0.3, 0.8]
# Example database
VECTOR_DATABASE = [
[0.1, 0.2, 0.9],
[0.8, 0.7, 0.3],
[0.4, 0.1, 0.5]
]
def cosine_similarity(vec1, vec2):
dot_product = sum(a * b for a, b in zip(vec1, vec2))
magnitude1 = math.sqrt(sum(a * a for a in vec1))
magnitude2 = math.sqrt(sum(b * b for b in vec2))
return dot_product / (magnitude1 * magnitude2)
# Find the closest vector to the query
similarities = [cosine_similarity(QUERY_VECTOR, vec) for vec in VECTOR_DATABASE]
most_similar_index = max(range(len(similarities)), key=lambda i: similarities[i])
# Output the most similar vector
print(f"Most similar vector: {VECTOR_DATABASE[most_similar_index]}")
print(f"Similarity score: {similarities[most_similar_index]}")
This script illustrates how vector search works at a basic level. In practice, as your dataset grows, you'll need a more efficient way to search and compare vectors. That's where using a dedicated vector database comes in handy.
Similarity search and distance metrics
Next, let's talk about how vector databases measure similarity. Here are two common ones:
- Euclidean distance measures the straight-line distance between two vectors. This is often used for clustering and classification tasks as the magnitude of the vectors is important (eg. GPS coordinates or RGB values).
- Cosine distance measures the cosine of the angle between two vectors, which represents how similar they are in direction (but not magnitude). This is often used for text similarity or recommendation systems.
But there are plenty of other distance metrics you could use. The choice depends on your data and the problem you're trying to solve.
Dimensionality reduction
Let's briefly touch on a common challenge with vector databases: the curse of dimensionality
When you're working with high-dimensional vectors, it can be hard to search and compare them efficiently. Not only that, but you might run into issues with overfitting and noise.
You can combat this by using dimensionality reduction techniques like principal component analysis (PCA) or t-SNE. This enables you to reduce the number of dimensions while preserving the most important information.
For example, you might reduce a 1000-dimensional vector to a 100-dimensional one like this:
from sklearn.decomposition import PCA
# Example embeddings with 1000 dimensions
vectors = [
[0.1, 0.2, ...],
[0.8, 0.7, ...],
[0.4, 0.1, ...]
]
# Reduce the vectors to 100 dimensions
pca = PCA(n_components=100)
reduced_vectors = pca.fit_transform(vectors)
print(reduced_vectors)
This is a common technique used in machine learning and data analysis to make high-dimensional data more manageable. While it's out of the scope of this guide, there's plenty other strategies you could consider such as autoencoders, feature selection, or regularization.
List of vector databases
Finally, let's wrap it up with a list of vector databases you could try out. This is by no means exhaustive, but should give you a good starting point:
- Qdrant: Open-source vector database with a focus on performance.
- pgvector: If you're already using Postgres, this is an easy upgrade. Also check out pgvectorscale, which optimizes for larger datasets and faster queries.
- sqlite-vec: Extends SQLite with vector search capabilities.
- Pinecone: Fully managed and easy to use.
- Convex: Real-time database that supports embeddings.
- Faiss: Facebook's library for similarity search.
- MeiliSearch: Open-source search engine with support for vectors.
- Chroma: Easy to use open-source vector database.
I hope this guide was helpful. If you have any questions or feedback, feel free to reach out to me on X.